Big organisations in information driven industries are gradually moving away from creating software data tools themselves. The task of creating software is getting outsourced to anyone with an interest in it by using an approach referred to as Model Driven Development (MDD). Considered a fanciful idea just a few years ago, MDD has moved from a novel concept to a pragmatic business necessity in large corporations. App store by Apple for iPhones is just one of the examples of the success of this approach. Implementing MDD in healthcare can prevent the sector from spending billions on complex IT projects, while delivering comparable or even better software tools.
The main benefits of such an approach in healthcare could be:
- Reduction in development cost and time
- Interoperability between different software
- Localised specifications to better address complex variable needs
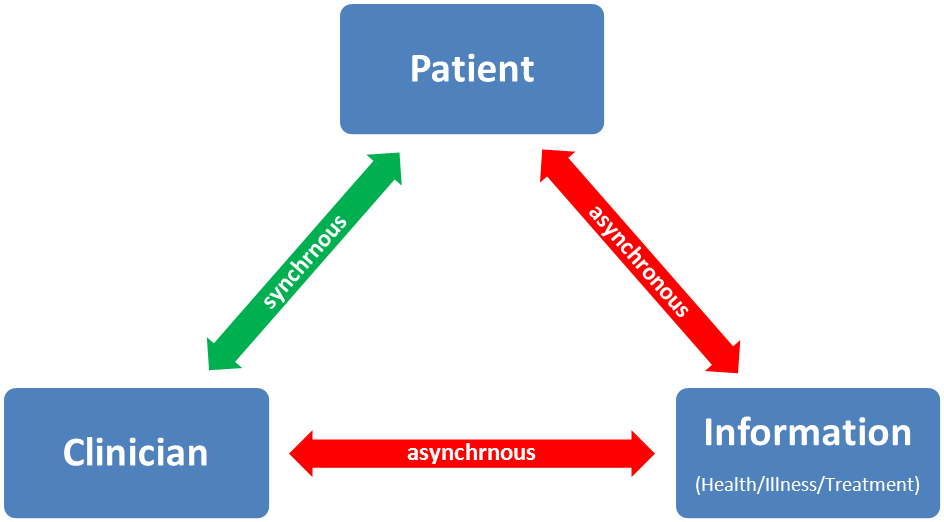
- Better opportunities for clinicians and patients to engage in software development
MDD approach requires the healthcare authorities to look at the healthcare IT as an ecosystem rather than as a project. It hence takes on the responsibility for establishing standards and benchmarking, providing an immense room for policy innovations. MDD software approaches have proven to be inherently adaptable to changing circumstances. This makes these approaches an excellent fit in healthcare settings wherein changes in government, technology or medical knowledge require resilient IT solutions (“future proofing”).
Healthcare IT can benefit by learning from other information driven industries. However in most cases, the project leadership is unable to see the big picture in both IT and health industry. This is because in healthcare, creator of technological and data solutions is not usually the consumer of these tools. To succeed and stay ahead of the curve, healthcare IT would need to foster leadership positions for people uniquely qualified to take on integrative leadership roles, which can facilitate such vision. In the UK, some healthcare authorities have started recruiting Chief Clinical Information Officers (CCIO) to their boards, which is an encouraging step towards this direction. Otherwise we would be perpetuating this strange dichotomy wherein patients and clinicians are technophiles at home with smartphones, but technophobes once inside healthcare settings. 1The content of this post was later included in a chapter in the following publication: Tyagi, H. (2013). Health data technologies: the current challenges. In NEXUS STRATEGIC PARTNERSHIPS (Ed.), Commonwealth Health Partnerships. London: Nexus Strategic Partnerships for the Commonwealth Secretariat.
footnotes
| ↑1 | The content of this post was later included in a chapter in the following publication: Tyagi, H. (2013). Health data technologies: the current challenges. In NEXUS STRATEGIC PARTNERSHIPS (Ed.), Commonwealth Health Partnerships. London: Nexus Strategic Partnerships for the Commonwealth Secretariat. |
|---|